%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Generative Models
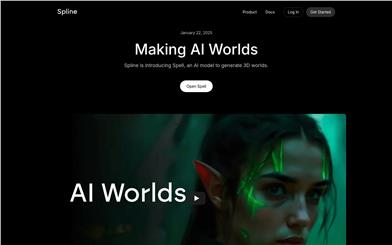
Spell By Spline
Spell is an AI model launched by Spline that can generate complete 3D scenes from a single image. It is based on diffusion model technology and trained by combining real and synthetic data, capable of producing 3D worlds with multi-view consistency in just a few minutes. The major advantage of this technology is its ability to generate high-quality 3D scenes quickly while supporting various rendering techniques such as Gaussian drawing and neural radiance fields. The advent of Spell has brought revolutionary changes to the field of 3D design, allowing creators to generate and explore 3D scenes more efficiently. Currently, Spell is still in development, and the team plans to frequently update the model to enhance quality and consistency.
3D Modeling
49.1K
Eurusprm Stage2
EurusPRM-Stage2 is a cutting-edge reinforcement learning model that optimizes the reasoning process of generative models using implicit process rewards. It calculates process rewards through the log-likelihood ratios of causal language models, improving the reasoning capabilities of the models without incurring additional annotation costs. Its primary advantage lies in its ability to learn process rewards implicitly using only response-level labels, thereby increasing the accuracy and reliability of generative models. The model excels in tasks such as mathematical problem solving, making it suitable for scenarios requiring complex reasoning and decision-making.
Model Training and Deployment
46.6K
Eurusprm Stage1
EurusPRM-Stage1 is part of the PRIME-RL project, which aims to enhance the reasoning capabilities of generative models through implicit process rewards. This model utilizes an implicit reward mechanism that doesn't require the additional labeling of process tags, allowing it to gain rewards during the reasoning process. Its key advantage is its ability to effectively improve the performance of generative models in complex tasks while reducing annotation costs. This model is suitable for scenarios that require complex reasoning and generation abilities, such as solving mathematical problems and generating natural language.
AI Model
44.7K
Flexrag
FlexRAG is a flexible and high-performance framework for Retrieval-Augmented Generation (RAG) tasks. It supports multimodal data, seamless configuration management, and out-of-the-box performance, making it suitable for research and prototyping. Written in Python, it combines lightweight design with high performance, significantly improving the speed of RAG workflows and reducing latency. Key advantages include support for multiple data types, unified configuration management, and ease of integration and extension.
Development & Tools
48.9K
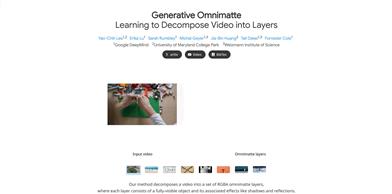
Generative Omnimatte
Generative Omnimatte is an advanced video processing technology that can decompose videos into multiple RGBA layers, with each layer capturing visible objects and their effects, such as shadows and reflections. This technology is significant in video editing and visual effects production, enhancing creative flexibility and efficiency.
Video Editing
46.6K
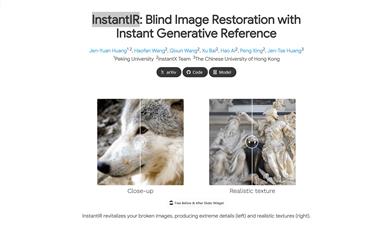
Instantir
InstantIR is a blind image restoration method based on diffusion models that can handle unknown degradation problems during testing, enhancing the model's generalization capabilities. This technology dynamically adjusts generation conditions by generating reference images during inference, thereby providing robust generation conditions. Key advantages of InstantIR include the ability to restore details in extremely degraded images, delivering realistic textures, and enabling creative image restoration through text descriptions. This technology has been jointly developed by researchers from Peking University, the InstantX team, and The Chinese University of Hong Kong, with sponsorship support from HuggingFace and fal.ai.
Image Editing
77.6K
Lfms
Liquid Foundation Models (LFMs) are a series of innovative generative AI models that achieve state-of-the-art performance across various scales while maintaining lower memory usage and higher inference efficiency. LFMs leverage computational units from dynamic systems theory, signal processing, and numerical linear algebra to handle all types of sequential data, including video, audio, text, time series, and signals. These models are general-purpose AI solutions designed to process large-scale, multimodal sequential data, enabling advanced reasoning and reliable decision-making.
Model Training and Deployment
52.7K
Stability AI
Stability AI is a company focused on generative artificial intelligence technology, offering a variety of AI models including text-to-image, video, audio, 3D, and language models. These models are capable of processing complex prompts, producing realistic images and videos, as well as high-quality music and sound effects. The company provides flexible licensing options, including self-hosted licenses and platform APIs, to meet diverse user needs. Stability AI is dedicated to offering high-quality AI services globally through open models.
Image Generation
78.7K
Fresh Picks
SV4D
Stable Video 4D (SV4D) is a generative model based on Stable Video Diffusion (SVD) and Stable Video 3D (SV3D). It takes a single perspective video and generates multiple new perspective videos (4D image matrix) of the same object. The model is trained to generate 40 frames (5 video frames x 8 camera angles) at a resolution of 576x576, given 5 reference frames of the same size. By running SV3D to produce a track video, this track video can then be used as a reference view for SV4D, with the original video serving as reference frames for 4D sampling. The model also generates longer new perspective videos by using the initial generated frame as an anchor point and performing dense sampling (interpolation) for the remaining frames.
AI video generation
60.4K
Fresh Picks
Cookbooks
Cookbooks is an online documentation platform provided by Cohere to guide developers and users in utilizing Cohere's generative AI platform to create diverse applications. It features tutorials for various use cases, including building agents, integrating open-source tools, semantic search, cloud services, retrieval-augmented generation (RAG), and summarization generation. These tutorials offer best practices, enabling users to maximize their use of Cohere's models, and all content is readily available for users to begin testing.
AI Development Assistant
53.5K
GLIGEN
GLIGEN is an open-ended image generation model based on textual prompts, capable of generating images based on textual descriptions and bounding boxes, among other constraints. This model achieves its capability by freezing pre-trained text-to-image Diffusion model parameters and inserting new data within them. Its modular design allows for efficient training and offers strong inferential flexibility. GLIGEN supports conditional image generation in an open world and possesses strong generalization capabilities for new concepts and layouts.
AI image generation
88.3K
SCEPTER
SCEPTER is an open-source code library dedicated to training, tuning, and inference for generative models, covering a range of downstream tasks such as image generation, transfer, and editing. It integrates mainstream implementations from the community as well as independently developed methods from Alibaba's Unisound Lab, offering a comprehensive and general-purpose toolkit for researchers and practitioners in the generative field. This versatile library aims to promote innovation and accelerate the progress of this rapidly evolving field.
AI Model
92.7K

Animatabledreamer
AnimatableDreamer is a framework for generating and reconstructing animatable non-rigid 3D models from single-eye videos. It is capable of creating non-rigid objects of different categories while adhering to the object movement extracted from the video. The key technology is the proposed canonical score distillation method, which simplifies the generation dimension from 4D to 3D, performs denoising across different frames in the video, and carries out the distillation process within a unique canonical space. This ensures consistent generation and realistic morphologies across different postures. With differentiable deformation, AnimatableDreamer elevates the 3D generator to 4D, providing a new perspective on the generation and reconstruction of non-rigid 3D models. Additionally, combining with the inductive knowledge of consistency diffusion models, canonical score distillation can regularize reconstruction from new perspectives, thereby enhancing the generative process in a closed loop. Extensive experiments demonstrate that this method can generate highly flexible 3D models guided by text from single-eye videos, while achieving superior reconstruction performance compared to typical non-rigid reconstruction methods.
AI 3D tools
56.3K
Alloydb AI
AlloyDB AI is a database service introduced by Google Cloud that assists developers in building generative AI applications on top of PostgreSQL. It offers a familiar PostgreSQL interface, supports vector and model management, and can deeply integrate Google Vertex AI for easy access to various generative AI models. AlloyDB AI features enterprise-grade scalability, availability, and security, enabling ultra-high-performance vector operations, making it an ideal choice for building generative AI applications on PostgreSQL.
AI Data Warehouse Query Construction
49.4K
Openai
OpenAI is dedicated to creating safe and beneficial artificial intelligence. Through research in generative models and alignment with human values, we are pioneering the path towards responsible AI. Our products, including ChatGPT and GPT-4D, empower individuals and businesses to harness the transformative power of AI in work and creativity. Our API platform enables developers to leverage cutting-edge models while adhering to best practices for safety and security. Join us in shaping the future of technology.
AI Content Generation
1.1M
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
45.5K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
43.3K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
44.2K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
43.6K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
43.6K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.7K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M